Creating a new programming language
Ever thought of creating your own programming language? It is not as daunting as it sounds. Here's my walkthrough of creating LISP, our new language, on top of JavaScript.
Before I kick off, a short note: I have written this content to go along with my ‘Logic, Math and Code‘.
Back to business:
2011. After my first LISP class, I was very intrigued by this new programming language. There was a beauty to it that I couldn't explain. It was one of the courses that I made sure not to miss.
In the last decade, I have learnt many languages. Programming languages kept getting fancier, like the laptops we use. With each new language, there is increasingly more noise about how to use it. There are many courses on "How to be great at this shiny new language". Without realizing it, we are creating a cloud over the crux of programming language. We are indirectly saying a programming language is mysterious—something you can only use but can't understand.
And that's what we are doing wrong to new developers and engineers. Once you lift that mysterious air about a language and take peek behind the curtain, I believe, you can learn and code in any programming language.
For me, that happened with LISP. LISP was what made me see the beauty of a language. The more I understood it, the more I felt comfortable with the concept of a programming language. LISP is rarely used these days. But for this post, it is perfect. I have an incentive to revisit fond memories of the language while recreating it in JS.
Here's what we will do: we build LISP (a new language) on the bed of JS. By doing that, I hope you get comfortable with the concept of a programming language. While we practice creating something from atoms, under the hood, I hope you appreciate the recursiveness of programming languages.
A short history
At the crux of a computing machine, we have memory and instructions. There are different forms of memory (cache, in-memory, disk etc.), but they all provide a way to store, update and read data. Then we have instructions that make the machine perform low-level operations and move data in memory around.
At the lowest level, we have binary code. These instructions are incredibly basic and limited, such as "add these two numbers" or "move this value from this memory address to another". Writing binary directly is impractical, so assembly language was developed. Assembly gave names to the various binary instructions (such as "ADD" or "MOV") and allowed us to write in a slightly more human-readable form.
Assembly, however, is still rather unwieldy and directly tied to the architecture of the specific processor you're programming for. Therefore, higher-level languages were developed that abstract away a lot of these details. Languages such as C allow you to write code that looks nothing like Assembly, but can still be compiled into it. Higher-level languages like Python, Ruby, or JavaScript offer even more abstractions.
In a sense, each language is built on top of at least one other layer (machine code), providing an increasing level of abstraction and ease of use. So here's where we start our journey. How about we build a language on top of one we already know?
LISP syntax
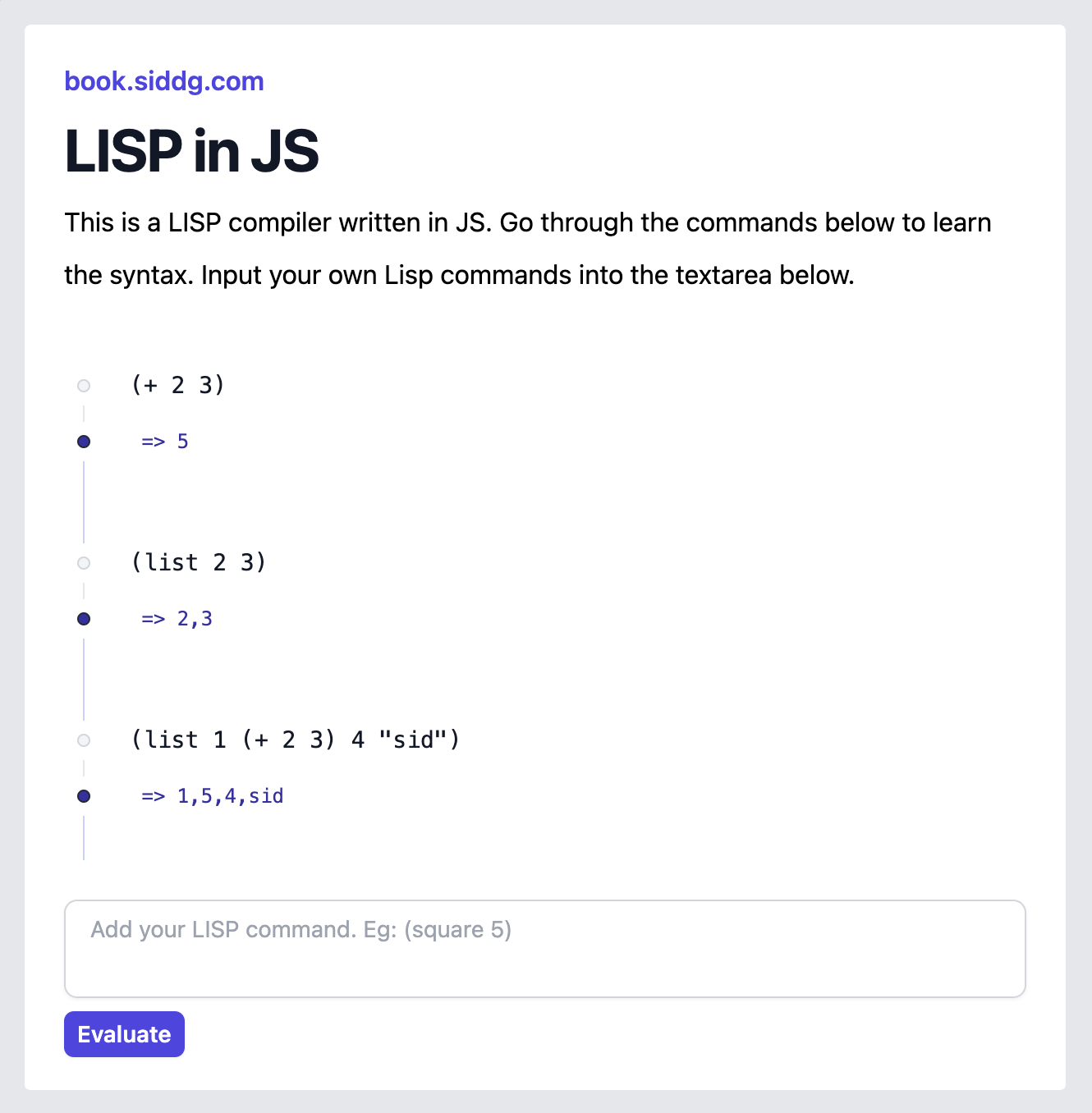
Here's the LISP syntax we want to support: (You can visit lisp-js.siddg.com on the side and execute these statements to become friendly with the syntax)
; This is a comment. Every thing that starts after semicolon is a comment.
(+ 2 3)
; every statement in LISP starts and ends with a bracket.
; each statement is a function.
; the contents of a statement start with the function name
; and rest are it's arguments
; (+ 2 3) => a function with name + and 2 and 3 as arguments.
(list 2 3)
; lists are fundamental atoms of LISP
; other fundamental atoms are numbers, strings, "symbols"
; a way to create a list is to call a function with name 'list'
; (list 2 3) => list with elements 2 and 3.
(list 1 (+ 2 3) 4 "sid")
; notice that you can nest statements
; (list 1 (+ 2 3) 4 "sid") => list with elements 1 5 4 "sid"
(first (list 1 2 3))
; first fn returns first element of the list
; (first (list 1 2 3)) => 1
(rest (list 1 2 3))
; rest fn returns rest of elements of the list after first.
; (rest (list 1 2 3)) => list with elements 2 and 3
(cons 2 (list 1 2 3))
; cons fn adds the first element to a list
; (cons 2 (list 1 2 3)) => list with elements 2 1 2 3
(length (list 1 2))
; length fn returns #elements in the list
; (length (list 1 2)) => 2
(> 2 4)
; > function behaves how you would expect it works on binary
; (> 2 4) => false
; so far we have seen base atoms
; and base functions/symbols that we want to support
; all of these base functions do not affect memory
; now let's provide a way to write and read from memory
(let ((x 10) (y 20))
(+ x y))
; let allows a way to set value to symbols and reuse them in a deeper statement
; above statement should return 30
; note that this way to set value to symbols is temporary
; symbols/ functions x and y doesn't mean anything outside 'let'
; that is where symbol set comes into the picture
(set x (list 1 2 3))
; function set takes a symbol and assigns it the value of the first argument
; (set x (list 1 2 3)) => x is saved as list with elements 1, 2, 3
; now we give a way to skip portions of code
(if (> 2 4) "two is > 4" "lesser")
; if is a symbol/ function that takes in 3 arguments
; first argument evaluates to either true or false
; depending on the response, second or third argument is returned
; now we have seen base symbols that affect memory
; now we empower the user of language by giving a way to define their own atoms
(define (square x) (* x x))
; define takes in a series of statements as arguments
; the first statement gives a function name and arguments of fn
; the rest of statements are the function body
; the result of the last statement in body is returned
; once a new symbol/ fn is defined, it is saved in memory so it can be used
(square 2)
; since square is defined above.
; (square 2) => 4
(set x 40)
(square x)
; => 1600
; and that's it. once we empower user with a way to create their own atoms
; they can chain, nest and build complex programs. here are some examples:
(define (sum-of-squares x y)
(+ (square x) (square y)))
(sum-of-squares 3 4)
; => 25
(define (! x) (if (< x 1) 1 (* x (! (- x 1)))))
(! 5)
; => returns 5!
(define (fibo x) (if (or (eql x 0) (eql x 1)) 1 (+ (fibo (- x 1)) (fibo (- x 2)))))
(fibo 10)
; returns 10th fibonacci number
(define
(reverse lst)
(if (eql (length lst) 0)
(list)
(append (reverse (rest lst)) (list (first lst)))
)
)
(reverse (list 1 2 3 4 5))
; => list with elements 5, 4, 3, 2, 1Get comfortable with the syntax of our new language. Once you are done, let's get cracking.
Let's define our goal: Given a LISP code as input, we want JS to "understand" the passed input and execute those instructions. i.e., perform changes to the memory and run computation operations.
We split this job into three tasks:
Parser: takes one big string with multiple LISP strings and breaks them down into a list of individual LISP strings.
Tokenizer: takes a LISP string, breaks it down and creates a token tree.
Interpreter: takes a tokenized string + memory and evaluates the string (i.e., support all the syntax forms we discussed above)
Parser
Here’s our Parser code: (the comments explain how it works)
/*
Given lisp code,
1. Parse it into well-formed individual statements
2. Use tokenizer to tokenize each statement
*/
function parser(lisp) {
// let's remove comments
// comment starts with ; and can appear in any line.
lisp = lisp
.split("\n")
.map((x) => x.split(";")[0])
.join("\n");
// let's convert lisp into well-formed individual statements
// (+ 2 3) -> well-formed individual statement
// (list 2 3) -> another well-formed individual statement
// simple brute-force algorithm to parse the lisp code character by character
// and splitting based on open and closing brackets
var statements = [];
var openBrackets = 0;
var currentStatement = "";
for (var i = 0; i < lisp.length; i++) {
var token = lisp[i];
currentStatement += token;
if (token === "(") {
openBrackets++;
}
if (token === ")") {
openBrackets--;
if (openBrackets === 0) {
statements.push(currentStatement);
currentStatement = "";
}
}
}
if (openBrackets !== 0) {
throw new Error("Unbalanced brackets");
}
if (currentStatement.length > 0) {
statements.push(currentStatement);
}
// now we have individual well formed statements to work on
// we will use tokenizer to tokenize each statement
// ... to be continued
}Now that we have an individual LISP statement, we need a tokeniser that converts it.
Tokenizer
Before we start coding, let's think about what we want the tokenizer to do.
Given a statement like ( …. some tokens…. (….some tokens….) (….some tokens…)), we want to split this into an array of children where each child is a token. If the token is a statement, we want the tokenizer to go one level down and tokenize it. If the token is not a statement, we analyze if it is a literal (number or string) or a symbol (a symbol has a meaning/ value from memory).
So (list 1 2 (list 3 (+ 4 5)) 6) should be converted into
[
{ children ->
list -> symbol
1 -> number
2 -> number
{ children ->
list -> symbol
3 -> number
{ children ->
+ -> symbol
4 -> number
5 -> number
}
}
6 -> number
}
]You can check the first array logged into the console in lisp-js.siddg.com. It contains a list of LISP statements and their tokenized statements.
Once you understand the structure of what we want, here's the tokenizer code:
/*
Given a series of tokens,
(+ 2 3) -> well-formed individual statement also works as list of tokens
// + 2 3 -> list of tokens
// list 1 2 "sid" (list 1 2) -> list of tokens
process it from left to right and return a array of analyzed tokens
// supported tokens
// 1. number
// 2. string
// 3. symbol --> anything that is not number of string or a bracket
// whenever a ( is encountered, tokenize the list of tokens inside the bracket into a separate object
*/
function tokenizer(seriesOfTokens) {
if (seriesOfTokens.length === 0) {
return [];
}
// The first token in the list is a well-formed individual statement
if (seriesOfTokens[0] === "(") {
// find the closing bracket
var openBrackets = 0;
var closingBracketIndex = -1;
for (var i = 0; i < seriesOfTokens.length; i++) {
if (seriesOfTokens[i] === "(") {
openBrackets++;
} else if (seriesOfTokens[i] === ")") {
openBrackets--;
if (openBrackets === 0) {
closingBracketIndex = i;
break;
}
}
}
// list of tokens inside this bracket
var tokensOfthisBracket = seriesOfTokens
.substring(1, closingBracketIndex)
.trim();
// rest of the tokens;
// remember seriesOfTokens might not be a well-formed individual statement.
// so there can be more tokens left to process.
// example if the original statement sent to tokenizer is (list 1 2) 3 4
// then we are going to tokenize (list 1 2) and 3 4 separately
var restOfTheTokens = seriesOfTokens
.substring(closingBracketIndex + 1)
.trim();
return [
{
children: [...tokenizer(tokensOfthisBracket)],
},
...tokenizer(restOfTheTokens),
];
}
// The first element in the list is the tokens is a string.
// strip the string and tokenize the rest of the tokens
if (seriesOfTokens[0] === '"') {
return [
{
type: "string",
stringContent: seriesOfTokens.substring(
1,
seriesOfTokens.indexOf('"', 1)
),
},
...tokenizer(
seriesOfTokens
.substring(seriesOfTokens.indexOf('"', 1) + 1)
.trim()
),
];
}
// Not a string. Not a (). What else could it be? analyze first word
var firstSpaceIndex = seriesOfTokens.indexOf(" ");
if (firstSpaceIndex === -1) {
firstSpaceIndex = seriesOfTokens.length;
}
var firstWord = seriesOfTokens.substring(0, firstSpaceIndex);
var restOfTheTokens = seriesOfTokens.substring(firstSpaceIndex + 1).trim();
if (!isNaN(firstWord)) {
// it is a number
return [
{
type: "number",
number: Number(firstWord),
},
...tokenizer(restOfTheTokens),
];
}
// it is a symbol. return it as it is. tokenizer is not smart enough to analyze what it is.
// it just says it is something to analyze
return [
{
type: "symbol",
symbol: firstWord,
},
...tokenizer(restOfTheTokens),
];
}Note here that the tokenizer always returns an array of tokens. But when we pass a well-formed statement, we expect an object with children instead of an array. We adjust for this when we pair the parser with the tokenizer. Here's the completed parser code:
/*
Given lisp code,
1. Parse it into well-formed individual statements
2. Use tokenizer to tokenize each statement
*/
function parser(lisp) {
// let's remove comments
// comment starts with ; and can appear in any line.
lisp = lisp
.split("\n")
.map((x) => x.split(";")[0])
.join("\n");
// let's convert lisp into well-formed individual statements
// (+ 2 3) -> well-formed individual statement
// (list 2 3) -> another well-formed individual statement
// simple brute-force algorithm to parse the lisp code character by character and splitting based on
// open and closing brackets
var statements = [];
var openBrackets = 0;
var currentStatement = "";
for (var i = 0; i < lisp.length; i++) {
var token = lisp[i];
currentStatement += token;
if (token === "(") {
openBrackets++;
}
if (token === ")") {
openBrackets--;
if (openBrackets === 0) {
statements.push(currentStatement);
currentStatement = "";
}
}
}
if (openBrackets !== 0) {
throw new Error("Unbalanced brackets");
}
if (currentStatement.length > 0) {
statements.push(currentStatement);
}
// now we have individual well formed statements to work on
// use tokenizer to tokenize each statement
var tokenizedStatements = statements
.filter((x) => x)
.map((x) => x.trim())
.filter((x) => x)
.map((statement) => {
var tokens = tokenizer(statement);
var tokenizedStatement = {
children: tokens,
}; // OR tokens[0]
// interpreter works on whole formed individual statements that are represented by objects
// tokenizer returns a list of tokens which themselves are objects
// so we can either send tokens[0] as the statement to interpreter
// OR
// form a wrapped object with children as tokens and send it to interpreter
// we are doing the latter because it is fun
return {
statement,
tokenizedStatement,
};
});
return tokenizedStatements;
}You can use our parser (with tokeniser inside) like this:
var lisp = `
(+ 2 3)
`;
const parsedOutput = parser(lisp);
console.log(parsedOutput);Interpreter
First, let's build a function 'interpret' that takes in a tokenized statement (object) and works on it. Here's the complete code of this function with proper comments to explain the logic flow:
/*
Given a tokenized statement, interpret/ evaluate it and return the result
env is the environment in which the statement is interpreted
*/
function interpret(statement, env) {
var type = statement.type;
// If we are dealing with atomic step
// i.e, 1 2 3 "sid" list square etc.
// return it's value from environment
if (type === "number") {
return Number(statement.number);
} else if (type === "string") {
return statement.stringContent;
} else if (type === "symbol") {
return env[statement.symbol];
}
// If it is not atomic, then it must have children
var children = statement.children;
// First children gives us the type of the statement to interpret
var firstItem = children[0];
var rest = children.slice(1);
var type = firstItem.type;
if (type === "symbol") {
// If it is a symbol, then it is a special form or a function call
var symbol = firstItem.symbol;
// "rest" then becomes the arguments to the special form or function call
// Special forms that we support
if (symbol === "list") {
return [...rest.map((x) => interpret(x, env))];
} else if (symbol === "first") {
return [...interpret(rest[0], env)][0];
} else if (symbol === "rest") {
return [...interpret(rest[0], env)].slice(1);
} else if (symbol === "last") {
return [...interpret(rest[0], env)].slice(-1)[0];
} else if (symbol === "cons") {
return [interpret(rest[0], env), ...interpret(rest[1], env)];
} else if (symbol === "append") {
return rest
.map((x) => interpret(x, env))
.reduce((a, b) => a.concat(b), []);
} else if (symbol === "length") {
return [...interpret(rest[0], env)].length;
} else if (symbol === "+") {
return [...rest.map((x) => interpret(x, env))].reduce(
(a, b) => a + b,
0
);
} else if (symbol === "-") {
const nums = [...rest.map((x) => interpret(x, env))];
if (nums.length === 0) {
// (-) -> 0
return 0;
} else if (nums.length === 1) {
// (- 2) => -2
return -1 * nums[0];
}
// (- a b c) => a - b - c
return nums[0] - nums.slice(1).reduce((a, b) => a + b, 0);
} else if (symbol === "*") {
return [...rest.map((x) => interpret(x, env))].reduce(
(a, b) => a * b,
1
);
} else if (symbol === "/") {
return [...rest.map((x) => interpret(x, env))].reduce(
(a, b) => a / b,
0
);
} else if (symbol === "%") {
return [...rest.map((x) => interpret(x, env))].reduce(
(a, b) => a % b,
0
);
} else if (symbol === ">") {
return interpret(rest[0], env) > interpret(rest[1], env);
} else if (symbol === "<") {
return interpret(rest[0], env) < interpret(rest[1], env);
} else if (symbol === ">=") {
return interpret(rest[0], env) >= interpret(rest[1], env);
} else if (symbol === "<=") {
return interpret(rest[0], env) <= interpret(rest[1], env);
} else if (symbol === "eql") {
return interpret(rest[0], env) === interpret(rest[1], env);
} else if (symbol === "or") {
return rest.map((x) => interpret(x, env)).some((x) => x);
} else if (symbol === "and") {
return rest.map((x) => interpret(x, env)).every((x) => x);
} else if (symbol === "let") {
const firstRest = rest[0];
const restRest = rest.slice(1);
const newEnv = { ...env };
for (var i = 0; i < firstRest.children.length; i++) {
const child = firstRest.children[i];
const symbol = child.children[0].symbol;
const value = interpret(child.children[1], env);
newEnv[symbol] = value;
}
return interpret(restRest[restRest.length - 1], newEnv);
} else if (symbol === "set") {
const firstRest = rest[0];
const restRest = rest.slice(1);
const symbol = firstRest.symbol;
const value = interpret(restRest[0], env);
env[symbol] = value;
return value;
} else if (symbol === "define") {
const firstRest = rest[0];
const restRest = rest.slice(1);
const fnName = firstRest.children[0].symbol;
const fnArgs = firstRest.children.slice(1).map((x) => x.symbol);
const fnBody = restRest[0];
env[fnName] = {
fnArgs,
fnBody,
};
return fnName;
} else if (symbol === "if") {
const firstRest = rest[0];
const secondRest = rest[1];
const thirdRest = rest[2];
const condition = interpret(firstRest, env);
if (condition) {
return interpret(secondRest, env);
} else if (thirdRest) {
return interpret(thirdRest, env);
} else {
return false;
}
} else {
// check if this is a function call
if (env[symbol] && env[symbol].fnArgs) {
const fnArgs = env[symbol].fnArgs;
const fnBody = env[symbol].fnBody;
const newEnv = { ...env };
for (var i = 0; i < fnArgs.length; i++) {
newEnv[fnArgs[i]] = interpret(rest[i], newEnv);
}
return interpret(fnBody, newEnv);
} else {
return env[symbol];
}
}
} else {
return interpret(firstItem, env);
}
}Spend some time going back and forth between this code and the sample statements provided in lisp-js.siddg.com. The 'aha' moment comes when you understand how a new environment is spawned to make 'let' work. Then the bigger 'aha' comes when you understand how we make 'define' work to define a new user-defined function. And you are then giving the user ability to execute their functions along with passing data to their functions on-demand.
If you notice our parser, it returns a list of tokenized statements. Whereas our 'interpret' works on a single tokenized statement. Here's a wrapper (with some added functionality of showing us intermediate memory):
// Given a list of parsed statements, interpret them and return the result
// env is the environment in which the statements are interpreted
// for debugging purposes, we can pass debug=true to get the environment at each step
function interpreter(parsedStatements, env, debug) {
return parsedStatements.map((s) => {
const eval = interpret(s.tokenizedStatement, env);
return {
...s,
eval,
...(debug
? {
env: JSON.parse(JSON.stringify(env)),
}
: {}),
};
});
}That’s it. You can use our parser (with tokenizer) + interpreter like this:
var lisp = `
(+ 2 3)
`;
var env = {};
const interpretedOutput = interpreter(parser(lisp), env, (debug = true));
for (const x of interpretedOutput) {
console.log(`${x.statement} => ${x.eval}`, x.env);
}You can find the complete code (index.js) at https://github.com/siddug/lisp.js
It also has the HTML file that renders lisp-js.siddg.com, which uses our LISP-in-JS code to create an interactive editor.
Closing
Technically this new "language" is no different from the languages you learn and use today. We can create a few more special forms of this language to access the HTML DOM to make it more functional. We can create documentation, tutorials and the whole bazinga. With enough craze and popularity, everyone would use our new language and forget that it is simply an abstraction. And with that, I finish my Sunday meditation.
If you are still reading, thanks for hanging out with me. I hope you got something out of this. Here are some practice problems if you want to spend some time in the LISP-in-JS world before we head back to our daily "real" work.
/*
practice problems (doesn't require new syntax)):
- Find kth element of a list
- Find if a list is a palindrome
- Find index of an element in list
- Find minimum of an element in list
- Find if a list is sorted
- Find if a list has an element in it
- Intersection of lists
practice problems (add loop syntax):
- Find if a number is a prime
practice ux problems:
- Given a proper list statement, pretty print it with proper indentation (raise a PR to the repo)
practice library problems:
- Add forms to enable lisp-js to access DOM (example: (document.getElementById "id"))
*/More curious?
Want to try the old-school LISP or its variants? Replit has a functional Emacs LISP setup - here's the link.
Curious if anyone is using LISP? - here's a post from the Grammarly team talking about running LISP in prod.